4 Pronóstico jerárquico del IPC del Ecuador con ponderadores oficiales del INEC: comparación de modelos ETS y ARIMA mediante agregación bottom-up

Este estudio desarrolla un enfoque de pronóstico jerárquico para el índice de precios al consumidor (IPC) de Ecuador. Se utilizan 108 series mensuales desagregadas por ciudad y división de gasto, junto con los ponderadores oficiales del INEC, que definen la estructura de promedio ponderado del IPC nacional. A diferencia de la literatura tradicional de pronósticos jerárquicos, centrada en jerarquías aditivas donde los niveles superiores son sumas de los inferiores, este trabajo adopta una estrategia compatible con la naturaleza ponderada del IPC. Se estiman automáticamente modelos ETS y ARIMA sobre cada serie desagregada y los pronósticos se agregan coherentemente mediante un esquema bottom-up hasta obtener el IPC total. El desempeño se compara con modelos directos ETS y ARIMA estimados sobre el IPC agregado, evaluando un origen fijo y ventanas móviles de 12 meses. El enfoque bottom-up con ETS alcanza los menores errores, con un MAPE de 0.70 % frente a 1.67 % del mejor modelo directo. La mejora, sin embargo, no es uniforme entre divisiones de gasto ni horizontes de pronóstico. En conjunto, los resultados sugieren que, para este caso de estudio, el enfoque desagregado supera a los modelos agregados directos y permite generar proyecciones consistentes para niveles inferiores de la jerarquía.
inflación, pronóstico jerárquico, agregación ponderada, modelos ETS, validación predictiva
1 Introducción
En economías dolarizadas como la ecuatoriana, donde la política monetaria no constituye un instrumento disponible de ajuste, disponer de pronósticos precisos del índice de precios al consumidor (IPC) resulta especialmente relevante para la planificación fiscal, la toma de decisiones empresariales y el diseño de políticas públicas. La inflación afecta de manera directa el poder adquisitivo de los hogares, las decisiones de consumo e inversión y la formación de expectativas, por lo que mejorar la precisión de sus proyecciones constituye un objetivo empírico y aplicado de primer orden.
El IPC nacional es un índice agregado que se construye a partir de componentes desagregados por ciudad y división de gasto, combinados mediante ponderadores oficiales. Esta característica sugiere que su modelación puede abordarse no solo desde la serie agregada total, sino también desde sus componentes base. En principio, ello permite contrastar dos estrategias: una aproximación directa, que modela el IPC nacional como una única serie temporal, y una aproximación desagregada, que modela primero sus componentes y luego los agrega de forma coherente. La pertinencia de esta comparación es particularmente importante en el caso ecuatoriano, donde la estructura territorial y divisional del índice puede contener información relevante para el pronóstico agregado.
La literatura sobre pronósticos jerárquicos de series de tiempo ha mostrado que, bajo ciertas condiciones, la explotación de estructuras de agregación puede mejorar la coherencia y, en algunos casos, la precisión predictiva. Sin embargo, buena parte de esta literatura se ha desarrollado para contextos aditivos, en los que los niveles superiores de la jerarquía se obtienen como suma directa de las series de nivel inferior. En esos casos, métodos como la reconciliación estadística permiten garantizar consistencia entre niveles. Trabajos como los de Hyndman et al. (2011) y Wickramasuriya et al. (2018) se inscriben precisamente en este marco.
El IPC, no obstante, no constituye una jerarquía aditiva en sentido estricto. Sus agregaciones no responden a sumas simples, sino a combinaciones ponderadas que reflejan estructuras de gasto de los hogares. En consecuencia, trasladar de manera directa la lógica estándar de reconciliación aditiva no resulta plenamente adecuado. Este trabajo se sitúa precisamente en ese punto: propone una estrategia de pronóstico jerárquico no aditivo, en la que se modelan de manera independiente las series por ciudad y división de gasto, y posteriormente se reconstruyen los niveles superiores mediante agregación ponderada con los pesos oficiales del índice. De este modo, la propuesta no se limita a una aplicación empírica del enfoque bottom-up, sino que lo adapta a una estructura consistente con la forma en que el IPC ecuatoriano es efectivamente construido.
La novedad del artículo radica en una combinación de elementos. En primer lugar, plantea una formulación empírica compatible con la naturaleza no aditiva del IPC. En segundo lugar, implementa esa estrategia utilizando la desagregación oficial del índice ecuatoriano por ciudad y división de gasto. En tercer lugar, compara su desempeño frente a modelos directos estimados sobre el IPC nacional agregado, utilizando tanto especificaciones ETS como ARIMA bajo distintos esquemas de validación. En este sentido, la contribución del trabajo no reside únicamente en aplicar una metodología conocida al caso ecuatoriano, sino en adaptar el problema jerárquico a una estructura ponderada real y evaluar rigurosamente si esa adaptación produce ganancias de precisión predictiva.
A partir de lo anterior, la pregunta central de investigación es la siguiente: ¿un enfoque de pronóstico jerárquico no aditivo, basado en la modelación de componentes ciudad-división y su agregación mediante ponderadores oficiales, mejora la precisión del pronóstico del IPC nacional ecuatoriano frente a modelos directos estimados sobre la serie agregada? La hipótesis de trabajo es que la información contenida en la desagregación del índice permite obtener pronósticos más precisos del IPC total que aquellos derivados de la modelación directa de la serie nacional.
El resto del artículo se organiza de la siguiente manera. La segunda sección revisa la literatura relevante sobre pronóstico de inflación, modelos jerárquicos y aplicaciones relacionadas. La tercera sección describe los datos, la estructura del IPC, la estrategia de modelamiento y los esquemas de evaluación utilizados. La cuarta sección presenta y discute los resultados empíricos. Finalmente, la quinta sección expone las principales conclusiones del estudio.
2 Revisión de la literatura
2.1 Pronóstico de inflación e IPC: enfoques univariados y multivariados
La literatura sobre pronóstico de inflación y del índice de precios al consumidor (IPC) se ha desarrollado principalmente a partir de dos tradiciones. La primera corresponde a los modelos univariados, como ARIMA, SARIMA y ETS, que explotan la propia dinámica temporal de la serie. La segunda corresponde a los modelos multivariados, como VAR, VECM y BVAR, que incorporan información adicional sobre variables monetarias, cambiarias, de costos o actividad económica. En términos generales, la elección entre ambos enfoques depende del objetivo del estudio, del horizonte de pronóstico y de la estabilidad estructural del proceso inflacionario.
Dentro del grupo multivariante, Lack (2006) muestra para el caso suizo que la combinación de pronósticos derivados de modelos VAR puede mejorar sustancialmente la calidad predictiva respecto a benchmarks más simples, mientras que Dahem (2015), para Túnez, encuentra que los enfoques bayesianos aplicados a modelos VAR y VECM pueden reducir el error de pronóstico cuando se comparan con alternativas autorregresivas más parsimoniosas. Ambos trabajos son relevantes porque subrayan que la ganancia predictiva asociada a incorporar más información depende de la forma en que dicha información se organiza, selecciona y combina.
En el terreno univariante, los modelos ARIMA siguen siendo una referencia habitual en el pronóstico del IPC. Nyoni (2019) por ejemplo, emplea un ARIMA para proyectar el IPC de Bélgica y lo utiliza como base para discutir la trayectoria futura de la inflación. Este tipo de estudios confirma la utilidad de los modelos autorregresivos integrados de media móvil como benchmark parsimonioso, especialmente cuando el objetivo es evaluar precisión predictiva más que identificar relaciones estructurales. Sin embargo, la mayor parte de estos trabajos modela directamente la serie agregada del IPC y no explota la estructura interna del índice.
Más recientemente, Barkan et al. (2023) desarrollan un enfoque basado en redes neuronales jerárquicas para pronosticar componentes del IPC, mostrando que la explotación explícita de la estructura desagregada puede mejorar el desempeño predictivo frente a modelos agregados convencionales. Este tipo de evidencia es relevante para el presente trabajo porque sugiere que la desagregación no solo tiene valor descriptivo, sino también contenido predictivo potencial.
2.2 Series jerárquicas, combinación de pronósticos y reconciliación
La literatura de series temporales jerárquicas (HTS) parte de la idea de que una variable agregada puede descomponerse en subseries organizadas en distintos niveles, de manera que el pronóstico puede construirse desde abajo hacia arriba (bottom-up), desde arriba hacia abajo (top-down) o a partir de una combinación óptima de pronósticos estimados en distintos niveles. Hyndman et al. (2011) formalizan esta discusión mostrando que, bajo estructuras aditivas, la combinación óptima puede mejorar la coherencia y, en ciertos casos, la precisión de los pronósticos jerárquicos. Más adelante, Hyndman et al. (2016) profundizan en la reconciliación eficiente para series jerárquicas y agrupadas, mientras que Wickramasuriya et al. (2018) desarrollan propuestas de reconciliación basadas en minimización de la traza.
El punto central de esta literatura es que la agregación puede aportar valor cuando las series de nivel inferior contienen heterogeneidad relevante, pero también que la conveniencia de bottom-up, top-down o reconciliación no puede establecerse de manera universal. Sánchez & Gavira-Durón (2016), por ejemplo, muestran para el caso de la demanda de visitantes internacionales a México que algunos métodos jerárquicos superan a los no jerárquicos bajo ciertos criterios, aunque no de forma sistemática. En un ejercicio similar, Alonso Cifuentes et al. (2019) comparan varias alternativas jerárquicas para la demanda de gasolina en Bogotá y encuentran que la mejor combinación de método y estructura puede variar según el problema empírico. Ayas-Ferrer (2019), por su parte, también documenta que los resultados dependen del tipo de estructura y del criterio de error utilizado. En conjunto, estos trabajos sugieren que la literatura HTS debe leerse menos como una receta universal y más como un conjunto de herramientas cuya utilidad depende del contexto y del benchmark considerado.
De forma complementaria, Hendry & Hubrich (2010) abordan el problema desde otra perspectiva: en lugar de reconciliar explícitamente jerarquías, comparan la conveniencia de combinar pronósticos desagregados o combinar información desagregada para pronosticar un agregado. Su contribución es especialmente relevante porque muestra que la ganancia predictiva no depende únicamente de la estructura jerárquica formal, sino también de cómo se incorpora la heterogeneidad de las series base al proceso de pronóstico del agregado. Esta discusión conecta directamente con el interés del presente artículo, donde el objetivo no es solo mantener coherencia entre niveles, sino evaluar si la información ciudad-división mejora el pronóstico del IPC nacional.
2.3 Índices ponderados y estructuras no aditivas
El problema metodológico del IPC difiere del de una jerarquía aditiva estándar. En una estructura jerárquica clásica, los niveles superiores se obtienen como suma directa de las series de nivel inferior. En cambio, el IPC se construye como un índice ponderado, donde la agregación depende de ponderadores de gasto y no de simples sumas. Esto significa que la matriz de agregación relevante no es puramente aditiva, sino una estructura de combinación lineal ponderada coherente con la metodología oficial del índice. Este rasgo es central para el caso ecuatoriano, cuya metodología base 2014 especifica ponderadores por ciudad y división de gasto a partir de la estructura de consumo de los hogares.
La distinción entre jerarquías aditivas y estructuras ponderadas es importante porque limita la aplicación directa de la reconciliación jerárquica convencional. En lugar de imponer coherencia mediante sumas, el problema exige reconstruir el agregado a partir de pronósticos desagregados utilizando los ponderadores oficiales. El antecedente más cercano en la literatura aplicada es el trabajo de Alonso-Cifuentes & Rivera (2017) para Colombia, donde la inflación mensual se modela a partir de componentes del IPC y luego se reconstruye el agregado mediante una aproximación “de abajo hacia arriba”. Esa contribución es especialmente pertinente porque traslada la lógica jerárquica a un índice de precios con arquitectura de ponderaciones, mostrando que el enfoque desagregado puede superar al pronóstico agregado en ciertos horizontes.
Fuera del ámbito estrictamente inflacionario, Serrano-Hernandez (2024) propone un enfoque híbrido para el pronóstico jerárquico del consumo eléctrico industrial en Brasil, combinando modelos ETS y Box-Jenkins dentro de una estructura regional-estatal. Aunque el objeto de estudio es distinto, el trabajo es útil como antecedente metodológico porque confirma que, aun fuera de las jerarquías aditivas simples, la explotación de información granular puede traducirse en mejores resultados predictivos cuando la estructura del fenómeno está bien representada.
En este contexto, la contribución del presente artículo se ubica en la intersección entre la literatura HTS y la literatura de índices ponderados. Más que aplicar mecánicamente bottom-up al caso ecuatoriano, el estudio adapta la lógica jerárquica a una estructura no aditiva, consistente con la forma en que el IPC es efectivamente calculado.
2.4 Evidencia para Ecuador
Para Ecuador, la literatura sobre inflación se ha concentrado sobre todo en modelos agregados y en la identificación de determinantes macroeconómicos. Alarcón-Valverde & Chuñir-Panjón (2012) comparan modelos SARIMA y VECM para el pronóstico de la inflación ecuatoriana en el corto plazo, encontrando que ambas familias son competitivas bajo ciertos criterios de error. Erráez (2005) combina modelos ARIMA y VAR para estudiar el proceso inflacionario desde el inicio de la dolarización, mientras que Gachet et al. (2008) emplean un VAR estructural para analizar los determinantes de la inflación en una economía dolarizada. Morán-Chiquito (2014) y Calderón-Brito et al. (2019) también trabajan con enfoques multivariados sobre inflación ecuatoriana, centrando el análisis en variables como salarios, gasto público, oferta monetaria y tipo de cambio real. En todos estos casos, el énfasis está puesto en la explicación macroeconómica del IPC o de la inflación agregada, más que en la explotación de la estructura interna del índice.
Lo que permanece poco desarrollado en la literatura ecuatoriana es la posibilidad de utilizar la desagregación oficial del IPC por ciudad y división de gasto como base para pronosticar el índice agregado. En otras palabras, los estudios locales han tratado el IPC principalmente como una sola serie nacional o como una variable dependiente explicada por fundamentos macroeconómicos, pero no han construido una estrategia empírica que combine modelamiento desagregado y agregación coherente con la metodología oficial del índice. La relevancia de este vacío se refuerza al considerar que, según el Instituto Nacional de Estadística y Censos (2023), el IPC ecuatoriano se organiza sobre una estructura por ciudades autorrepresentadas y divisiones de consumo, con ponderadores fijos de gasto.
A partir de este vacío, el presente estudio propone una estrategia de pronóstico jerárquico no aditivo para el IPC ecuatoriano, basada en la estimación de modelos ETS y ARIMA sobre series ciudad-división y su posterior agregación mediante ponderadores oficiales. La contribución no reside únicamente en aplicar un enfoque desagregado al caso ecuatoriano, sino en hacerlo bajo una arquitectura metodológica compatible con la naturaleza ponderada del índice y contrastarlo empíricamente frente a benchmarks agregados directos. En ese sentido, el artículo se inserta en una línea de investigación todavía incipiente para el caso ecuatoriano y dialoga con la literatura internacional sobre jerarquías, combinación de pronósticos e índices compuestos.
3 Materiales y métodos
3.1 Estructura del IPC en Ecuador
El índice de precios al consumidor (IPC) del Ecuador se construye con base en la Clasificación del Consumo Individual por Finalidades (CCIF), lo que asegura comparabilidad internacional en la organización de los gastos de consumo. En el caso ecuatoriano, el indicador adopta las doce primeras divisiones de la CCIF, mientras que las dos últimas —correspondientes al gasto de las instituciones sin fines de lucro y del gobierno— no forman parte de la estructura del IPC de consumo de los hogares.
Tal como se muestra en la figura 1, la arquitectura completa del índice comprende varios niveles de desagregación. A partir del IPC total se distinguen 12 divisiones, que a su vez se descomponen en 43 grupos, 93 clases, 125 subclases y 359 productos. En el operativo estadístico del INEC, estos productos se sustentan además en un levantamiento mensual de artículos y tomas de precios a un nivel aún más detallado. Por tanto, el IPC oficial dispone de una estructura jerárquica más profunda que la utilizada en este estudio.
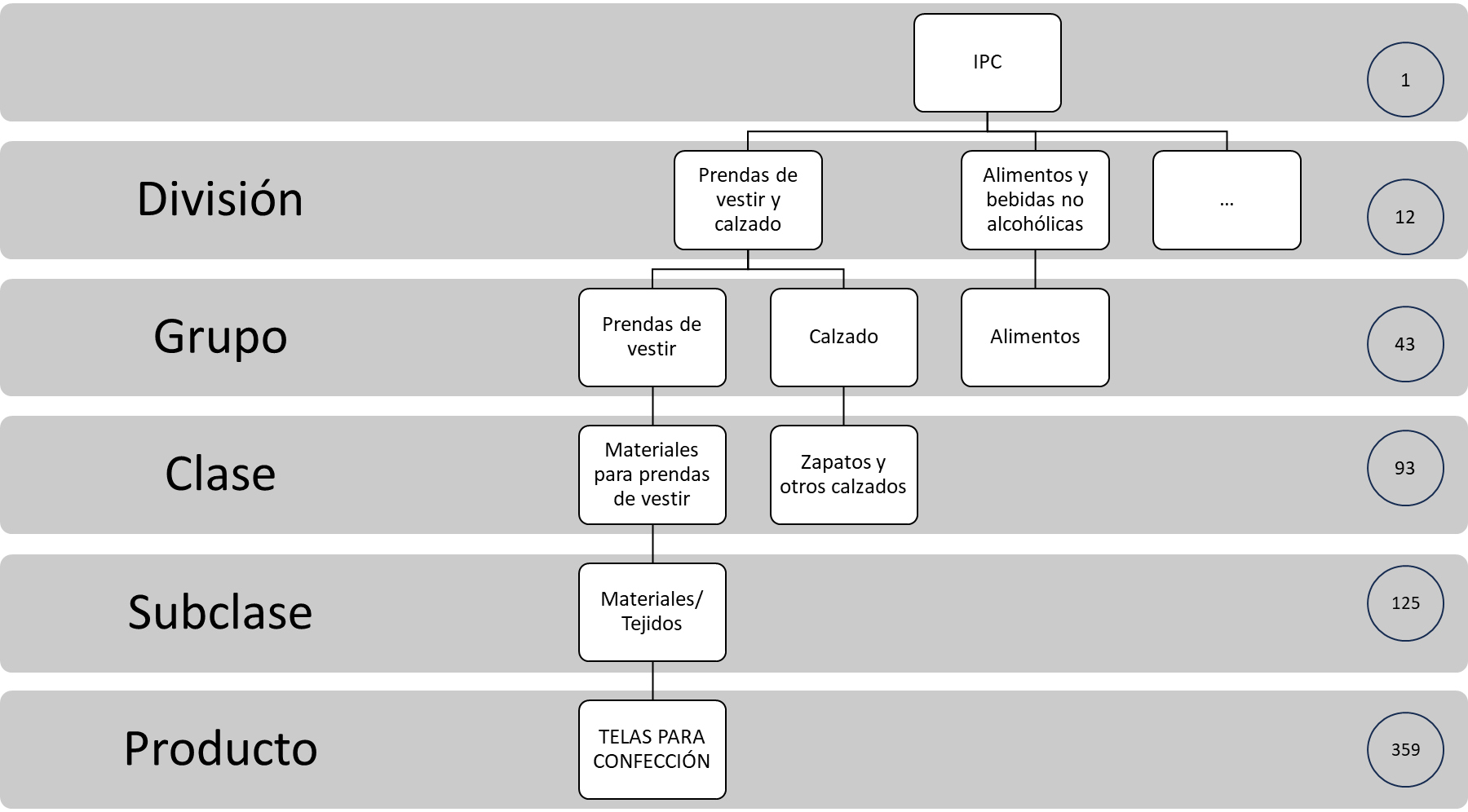
Fuente: INEC
Elaboración: autor
No obstante, el presente trabajo se detiene deliberadamente en el nivel de división. Es decir, aunque el INEC organiza el indicador hasta niveles más finos, aquí se utilizan las 12 divisiones por cada una de las 9 ciudades consideradas, lo que da origen a las 108 series base del ejercicio empírico. Esta decisión responde a dos razones. En primer lugar, el nivel división mantiene una desagregación suficiente para capturar heterogeneidad territorial y sectorial relevante para el pronóstico. En segundo lugar, evita incorporar ruido adicional derivado de niveles excesivamente granulares, donde la volatilidad idiosincrática puede deteriorar la estabilidad de los modelos y dificultar la comparación con el índice agregado.
En consecuencia, la estrategia empírica no pretende reproducir toda la profundidad clasificatoria del IPC oficial, sino utilizar un nivel de desagregación intermedio que sea metodológicamente consistente con la estructura del índice y, al mismo tiempo, operativo para fines de pronóstico.
3.2 Datos, cobertura y estructura jerárquica
El presente estudio utiliza información mensual del IPC del Ecuador publicada por el Instituto Nacional de Estadística y Censos (INEC), con cobertura desde enero de 2015 hasta junio de 2025. La base empleada contiene tanto el índice nacional agregado como sus componentes desagregados por ciudad y división de gasto, que constituyen la unidad mínima de modelación en este trabajo.
La estructura analítica utilizada se resume en la tabla 1. En total, la base comprende 13608 registros mensuales, organizados en 108 series base, construidas a partir de la combinación de 9 ciudades y 12 divisiones de consumo. Este panel balanceado resulta especialmente conveniente para la comparación entre enfoques de pronóstico, ya que evita asimetrías de cobertura entre series y reduce problemas asociados a datos faltantes.
| Característica | Valor |
|---|---|
| Frecuencia | Mensual |
| Período | 2015-01 a 2025-06 |
| Número total de observaciones | 13608 |
| Número de series base | 108 |
| Niveles jerárquicos | Región → Ciudad → División |
| Número de regiones | 2 |
| Número de ciudades | 9 |
| Número de divisiones | 12 |
| Series por ciudad | 12 |
| Observaciones por serie base | 126 |
| Distribución de registros | 108 series × 126 meses = 13608 registros |
| Ponderadores usados | Ponderadores oficiales del IPC base 2014 por división, ciudad y región |
| Criterio de exclusión | Ninguno; se conservaron únicamente series con cobertura mensual completa y sin valores faltantes. |
Fuente: INEC
Elaboración: autor
Una pieza central de la metodología corresponde a los ponderadores oficiales del IPC base 2014, empleados tanto en la construcción del índice como en la agregación de los pronósticos. En particular, se utilizan ponderadores por división dentro de cada ciudad, por ciudad dentro de cada región y por región dentro del total nacional. Dado que estos ponderadores se derivan de la estructura de gasto de la ENIGHUR base 2014, se mantienen fijos a lo largo del período analizado.
Desde el punto de vista empírico, el problema tiene una estructura jerárquica, pero no aditiva en sentido estricto. A diferencia de una jerarquía convencional por sumas, los niveles superiores del IPC no se obtienen como suma simple de subseries, sino mediante agregación ponderada. En consecuencia, la estrategia propuesta no recurre a reconciliación aditiva clásica, sino al modelamiento individual de las series base ciudad-división y a la reconstrucción posterior del índice agregado mediante ponderadores oficiales.
3.3 Cálculo de la agregación del IPC y de los pronósticos
Desde el punto de vista metodológico, el IPC ecuatoriano responde a la lógica de un índice de Laspeyres de base fija, en el que las variaciones de precios se valoran con ponderaciones de gasto del período base. En forma general, el índice puede expresarse como:
\[P_{t}^{L} = \frac{\sum_{i = 1}^{n}p_{i}^{t}q_{i}^{0}}{\sum_{i = 1}^{n}p_{i}^{0}q_{i}^{0}} = \sum_{i = 1}^{N}\left( \frac{p_{i}^{t}}{p_{i}^{0}} \right)s_{i}^{0} \tag{1}\]
donde \(p_{i}^{t}\) y \(p_{i}^{0}\) representan los precios del bien \(i\) en el período \(t\) y en el período base, respectivamente, \(q_{i}^{0}\) es la cantidad consumida en el período base y \(s_{i}^{0}\) corresponde a la participación del gasto del bien \(i\) en dicho período. Esta formulación resume el principio que subyace a la construcción del IPC: la agregación se realiza mediante ponderadores fijos asociados a la estructura de gasto de los hogares.
En la práctica, el INEC calcula primero índices elementales y luego los agrega secuencialmente a través de los distintos niveles de la canasta. Para los fines de este artículo, no se reconstruye toda esa cadena desde producto o artículo, sino que se trabaja directamente con el nivel de división, que constituye el nivel más desagregado disponible en la base utilizada. Por tanto, si \(y_{c,d,t}\) denota el índice observado de la división \(d\) en la ciudad \(c\) y en el período \(t\), el índice total de la ciudad \(c\) puede representarse como una combinación ponderada de sus divisiones:
\[y_{c,t} = \sum_{d=1}^{D}\omega_{c,d}\, y_{c,d,t} \quad \text{con} \quad \sum_{d=1}^{D}\omega_{c,d} = 1 \tag{2}\]
donde \(\omega_{c,d}\) es el ponderador oficial de la división \(d\) dentro de la ciudad \(c\), y \(D = 12\) es el número de divisiones consideradas en el estudio.
De manera análoga, el índice regional puede expresarse como una agregación ponderada de los índices de ciudad. Si \(r\) denota una región y \(C_{r}\) el conjunto de ciudades que pertenecen a ella, entonces:
\[y_{r,t} = \sum_{c \in C_{r}}\omega_{r,c}\, y_{c,t}, \quad \sum_{c \in C_{r}}\omega_{r,c} = 1 \tag{3}\]
donde \(\omega_{r,c}\) representa el peso relativo de la ciudad \(c\) dentro de la región \(r\). Finalmente, el IPC nacional agregado se obtiene como:
\[y_{t} = \sum_{r=1}^{R}\omega_{r}\, y_{r,t}, \quad \sum_{r=1}^{R}\omega_{r} = 1 \tag{4}\]
donde \(\omega_{r}\) es el ponderador de la región \(r\) en el índice nacional y \(R\) es el número de regiones consideradas en el estudio. Esta formulación sintetiza la arquitectura de agregación utilizada en el trabajo: división \(\rightarrow\) ciudad \(\rightarrow\) región \(\rightarrow\) nacional.
A partir de esta estructura, el estudio define la regla de agregación de pronósticos de forma análoga. Si \({\hat{y}}_{c,d,t + h \mid t}\) denota el pronóstico del índice de la división \(d\) en la ciudad \(c\), generado en \(t\) para el horizonte \(t + h\), entonces el pronóstico agregado por ciudad se obtiene como:
\[\hat{y}_{c,t+h \mid t} = \sum_{d=1}^{D}\omega_{c,d}\, \hat{y}_{c,d,t+h \mid t} \tag{5}\]
A su vez, el pronóstico regional y el pronóstico nacional se construyen como:
\[\hat{y}_{r,t+h \mid t} = \sum_{c \in C_{r}}\omega_{r,c}\, \hat{y}_{c,t+h \mid t} \tag{6}\]
\[\hat{y}_{t+h \mid t} = \sum_{r=1}^{R}\omega_{r}\, \hat{y}_{r,t+h \mid t} \tag{7}\]
En consecuencia, la coherencia entre niveles no se define en este trabajo como una igualdad por sumas simples, como ocurre en la reconciliación jerárquica clásica, sino como el cumplimiento de estas identidades de agregación ponderada para cada horizonte de pronóstico. Es decir, un conjunto de pronósticos se considera coherente si el pronóstico de ciudad coincide con la combinación ponderada de sus divisiones, el pronóstico regional coincide con la combinación ponderada de sus ciudades y el pronóstico nacional coincide con la combinación ponderada de sus regiones.
3.4 Estrategia de modelamiento y generación de pronósticos
Para la implementación empírica se definieron dos enfoques de pronóstico. El primero corresponde a un enfoque desagregado jerárquico no aditivo, en el que se modelan por separado las series mensuales identificadas por la combinación región-ciudad-división. El segundo corresponde a un enfoque directo agregado, en el que se modela de forma univariante la serie mensual del IPC nacional total. En ambos casos, el objetivo final de comparación es siempre el mismo: el pronóstico del IPC nacional.
Como transformación preliminar, las series se modelan en escala logarítmica, es decir, sobre \(x_{t} = \log(Y_{t})\), donde \(Y_{t}\) representa el nivel del índice. A partir de esta especificación, los pronósticos se generan inicialmente en escala logarítmica; sin embargo, al utilizar la infraestructura de fabletools, librería de R, la función forecast() realiza internamente la retransformación a la escala original del IPC. En consecuencia, los pronósticos puntuales empleados en el análisis y en la agregación jerárquica corresponden a valores del índice en niveles y no a logaritmos. Por tanto, la agregación ponderada entre divisiones, ciudades, regiones y total nacional se efectúa exclusivamente sobre pronósticos retransformados, manteniendo la consistencia entre la escala de estimación y la escala final de evaluación.
En particular, se utilizaron dos familias de modelos: ETS y ARIMA. En la familia ETS, la selección automática identifica la combinación más adecuada de componentes de error, tendencia y estacionalidad, permitiendo variantes con o sin tendencia, con o sin amortiguamiento, y con estructuras estacionales aditivas o multiplicativas. La distribución resumida de estas familias y componentes se presenta en el anexo 2.
De forma general, un modelo ETS puede representarse mediante la ecuación de pronóstico:
\[\hat{y}_{t+h \mid t} = \ell_t + hb_{t} + s_{t-m+h_{m}^{+}} \tag{8}\]
donde \(\ell_t\) representa el nivel; \(b_{t}\), la pendiente o tendencia; \(s_{t}\), el componente estacional, y \(m\), la periodicidad. En su forma aditiva, las ecuaciones de actualización pueden escribirse como:
\[\ell_{t} = \alpha\left(y_{t} - s_{t-m}\right) + (1-\alpha)\left(\ell_{t-1} + b_{t-1}\right) \tag{9}\]
\[b_{t} = \beta\left(\ell_{t} - \ell_{t-1}\right) + (1-\beta)b_{t-1} \tag{10}\]
\[s_{t} = \gamma\left(y_{t} - \ell_{t-1} - b_{t-1}\right) + (1-\gamma)s_{t-m} \tag{11}\]
donde \(\alpha\), \(\beta\) y \(\gamma\) son parámetros de suavizamiento. En la práctica, la rutina selecciona automáticamente la especificación ETS final en función de la estructura de la serie.
En la familia ARIMA, la detección automática permite identificar la presencia de persistencia, diferenciación y patrones estacionales, seleccionando los órdenes más adecuados del modelo. Su representación general puede escribirse como:
\[\Phi\left( B^{m} \right)\phi(B)(1 - B)^{d}\left( 1 - B^{m} \right)^{D}x_{t} = \Theta\left( B^{m} \right)\theta(B)\varepsilon_{t} \tag{12}\]
donde \(B\) es el operador rezago; \(d\) y \(D\) son los órdenes de diferenciación regular y estacional, respectivamente; \(\phi(B)\) y \(\Phi(B^{m})\) representan los componentes autorregresivos; \(\theta(B)\) y \(\Theta(B^{m})\), los componentes de medias móviles, y \(\varepsilon_{t}\) es un término de error de ruido blanco. En este caso, la rutina de selección automática determina los órdenes \(\left( p,d,q \right)\) y \(\left( P,D,Q \right)\) más apropiados para cada serie.
Sobre esta base, en el enfoque desagregado se estimaron modelos ETS y ARIMA para cada una de las 108 series ciudad-división. Los pronósticos obtenidos se agregaron posteriormente mediante los ponderadores oficiales del IPC, en una secuencia ascendente: primero a nivel ciudad, luego a nivel región y finalmente a nivel nacional. En el enfoque directo, en cambio, se estimaron modelos ETS y ARIMA directamente sobre la serie agregada del IPC total nacional.
La evaluación empírica se realizó en dos etapas. En primer lugar, se empleó un esquema de pronóstico desde un único punto de origen, en el cual los modelos se estiman una sola vez sobre una ventana inicial fija de entrenamiento compuesta por los primeros 112 registros mensuales y, a partir de esa estimación, se generan pronósticos para horizontes crecientes \(h = 1,2,\ldots,H\), sin reestimación de parámetros. Este diseño permite analizar de forma controlada cómo cambia el error de pronóstico conforme aumenta el horizonte temporal, manteniendo constante el conjunto de información utilizado para estimar el modelo.
En segundo lugar, se aplicó un ejercicio de sensibilidad mediante ventana rodante (rolling window). En este caso, se mantuvo fijo el tamaño de la muestra de entrenamiento en 108 observaciones mensuales, y en cada iteración la ventana se desplazó un período hacia adelante, incorporando una nueva observación y descartando la más antigua. Para cada origen de estimación se generaron pronósticos a 12 meses, tanto para los modelos desagregados como para los modelos directos. Este esquema permite evaluar la estabilidad relativa de los métodos cuando se exige al modelo un horizonte fijo de pronóstico y una cantidad constante de información histórica.
Como parte del preprocesamiento, se aplicó la función tsclean() de la librería forecast sobre cada serie del conjunto de entrenamiento, con el objetivo de corregir observaciones atípicas transitorias que pudieran distorsionar la estimación de los modelos. Esta corrección se realizó exclusivamente sobre la muestra de entrenamiento y antes de generar los pronósticos, mientras que la muestra de evaluación se mantuvo inalterada. De este modo, se evita la incorporación de información futura en el proceso de limpieza y, por tanto, se reduce el riesgo de filtración de información (data leakage) en la validación pseudo-fuera de muestra. Un diagnóstico gráfico de las series con mayor número de correcciones se presenta en el anexo 1.
3.5 Métricas de evaluación del desempeño predictivo
El desempeño predictivo de los modelos se evaluó mediante tres métricas estándar: el error absoluto medio (MAE), el error porcentual absoluto medio (MAPE) y la raíz del error cuadrático medio (RMSE). Estas métricas se calcularon a partir de la diferencia entre el valor observado del IPC nacional, denotado por \(y_{t}\), y su correspondiente pronóstico, denotado por \({\hat{y}}_{t}\). Aunque la estimación se realiza sobre \(\log(Y_{t})\), las métricas de evaluación se calculan sobre el IPC observado y pronosticado en su escala original.
Formalmente, las métricas utilizadas se definen como:
\[MAE = \frac{1}{n}\sum_{t=1}^{n}\left|y_{t} - \hat{y}_{t}\right| \tag{13}\]
\[MAPE = \frac{100}{n}\sum_{t=1}^{n}\left|\frac{y_{t} - \hat{y}_{t}}{y_{t}}\right| \tag{14}\]
\[RMSE = \sqrt{\frac{1}{n}\sum_{t=1}^{n}\left(y_{t} - \hat{y}_{t}\right)^{2}} \tag{15}\]
donde \(n\) representa el número de pronósticos evaluados.
En el esquema de origen fijo, \(n\) coincide con el número de horizontes considerados, ya que para cada horizonte \(h\) se compara el pronóstico correspondiente con el valor efectivamente observado del IPC nacional. Bajo este diseño, las métricas resumen el error asociado a la trayectoria pronosticada desde una única estimación inicial y permiten evaluar el deterioro o la persistencia de la precisión conforme se amplía el horizonte de predicción.
En el esquema de ventana rodante, en cambio, para cada origen de estimación se generan 12 pronósticos mensuales consecutivos y las métricas se calculan como promedios sobre ese bloque de pronósticos. En consecuencia, cada ejecución produce un valor promedio de MAE, MAPE y RMSE, lo que permite comparar la estabilidad del desempeño predictivo de los distintos métodos a lo largo de múltiples ventanas de estimación. Este procedimiento resulta particularmente útil para examinar la sensibilidad del pronóstico cuando se mantiene constante el tamaño de la muestra y se exige al modelo un horizonte relativamente más largo.
Desde el punto de vista interpretativo, el MAE mide el error absoluto promedio en unidades del índice, el MAPE expresa el error promedio en términos porcentuales, lo que facilita la comparación entre métodos, y el RMSE penaliza más severamente los errores grandes, por lo que resulta útil para identificar métodos que generan episodios de desviación más pronunciada. En conjunto, estas tres métricas ofrecen una evaluación complementaria de la precisión predictiva
4 Resultados y limitaciones
4.1 Evaluación de pronósticos estáticos
El primer ejercicio de validación se realizó bajo un esquema de pronóstico desde un único punto de origen, en el cual los modelos se estiman una sola vez sobre una ventana inicial fija y, a partir de esa estimación, se generan pronósticos para horizontes crecientes sin reentrenamiento intermedio. Bajo este diseño se compararon cuatro alternativas: el enfoque bottom-up no aditivo con ETS (BU_ETS); el enfoque bottom-up no aditivo con ARIMA (BU_ARIMA); el modelo ETS directo sobre el IPC total nacional (DIR_ETS), y el modelo ARIMA directo sobre el IPC total nacional (DIR_ARIMA).
La figura 2 muestra la evolución del MAPE por horizonte de pronóstico entre mayo de 2024 y junio de 2025. El patrón general es claro: los cuatro métodos presentan un deterioro gradual de la precisión a medida que el horizonte se amplía, pero este deterioro es sustancialmente menor en el enfoque desagregado, en particular en la especificación BU_ETS. En casi todos los meses evaluados, BU_ETS mantiene los menores errores porcentuales, seguido por BU_ARIMA, mientras que los modelos directos registran errores sistemáticamente más altos, especialmente a partir del cierre de 2024 y durante los primeros meses de 2025.
Este comportamiento también se refleja en los indicadores agregados de desempeño. Los valores consolidados se presentan en el anexo 3, y confirman que el método con mejor precisión global es bottom-up (BU_ETS), con un MAE de 0.78, un MAPE de 0.70 % y un RMSE de 1.06. En segundo lugar, se ubica bottom-up ARIMA (BU_ARIMA), con un MAE de 1.34, un MAPE de 1.18 % y un RMSE de 1.57. En contraste, los modelos directos presentan errores considerablemente mayores: ETS (DIR_ETS) alcanza un MAPE de 1.67 % y ARIMA (DIR_ARIMA) un MAPE de 1.81 %, además de registrar los mayores valores de MAE y RMSE.
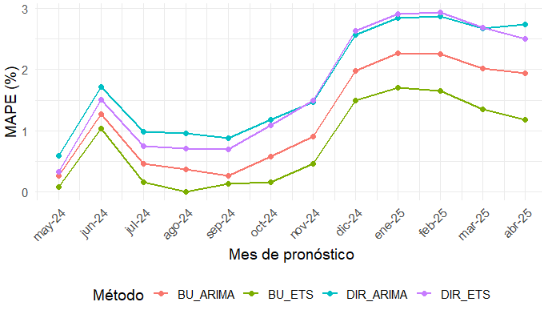
Fuente: INEC
Elaboración: autor
Desde el punto de vista económico, este resultado indica que la desagregación de la información contiene señales útiles que se pierden cuando el IPC total se modela como una única serie. La ventaja del enfoque bottom-up no aditivo parece provenir de su capacidad para capturar heterogeneidad entre divisiones y ciudades, y luego reconstruir el índice nacional respetando la estructura real de ponderaciones del IPC.
Con el fin de complementar la comparación de desempeño a nivel agregado, se descompuso el error del enfoque bottom-up en sus unidades base de modelación, esto es, por división y por ciudad, utilizando como criterio principal el MAPE. Esta desagregación permite identificar con mayor precisión en qué componentes de la estructura del IPC se concentran las mayores dificultades predictivas, y evita que el buen desempeño del índice agregado oculte heterogeneidades relevantes a nivel territorial y sectorial.
Los resultados por división muestran un patrón claramente diferenciado. En ambos métodos bottom‑up, la división alojamiento, agua, electricidad, gas y otros combustibles concentra el mayor error porcentual, con un MAPE de 9.42 % en BU_ETS y 9.64 % en BU_ARIMA, muy por encima del resto de divisiones. Esta brecha sugiere que se trata del componente más difícil de modelar dentro del sistema, posiblemente asociado a su mayor sensibilidad a ajustes discretos (revisiones tarifarias) y cambios no lineales en precios regulados, los cuales no son capturados de forma inmediata por los modelos automáticos empleados. La comprobación directa de esta relación requeriría un análisis específico de eventos regulatorios, que queda fuera del alcance de este estudio. A partir de allí, el comportamiento difiere entre métodos. En BU_ARIMA, las siguientes divisiones con mayor error son alimentos y bebidas no alcohólicas (1.80 %), recreación y cultura (1.46 %) y transporte (1.38 %). En BU_ETS, en cambio, los errores más altos, después de la división de alojamiento y combustibles, se observan en bebidas alcohólicas, tabaco y estupefacientes (1.77 %), recreación y cultura (1.32 %) y prendas de vestir y calzado (1.30 %). En términos generales, el mapa de calor por división confirma que BU_ETS presenta errores porcentuales inferiores a BU_ARIMA en la mayoría de componentes, y que la heterogeneidad entre divisiones es sustancial.
Fuente: INEC
Elaboración: autor
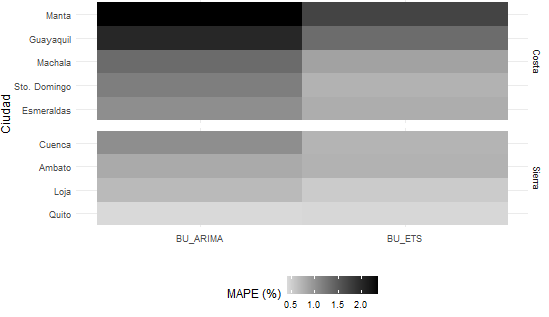
La desagregación por ciudad también revela diferencias relevantes en la dificultad predictiva. En ambos métodos, las ciudades con mayor MAPE se ubican en la Costa, particularmente Manta y Guayaquil. En el caso de BU_ARIMA, Manta registra un MAPE de 2.35 % y Guayaquil de 2.01 %, mientras que en BU_ETS esos valores se reducen a 1.70 % y 1.33 %, respectivamente. Después de estas ciudades, los mayores errores se observan en Machala y Santo Domingo para BU_ARIMA, y en Machala y Esmeraldas para BU_ETS. En contraste, las ciudades de la Sierra presentan un desempeño relativamente más estable, destacándose Quito y Loja como las de menor error porcentual en ambos métodos. En particular, Quito registra los menores valores de MAPE, con 0.42 % en BU_ARIMA y 0.43 % en BU_ETS, lo que sugiere una dinámica inflacionaria más predecible a este nivel de agregación.

Fuente: INEC
Elaboración: ator
Cuando se combinan ambas dimensiones —ciudad y división—, el patrón se vuelve aún más informativo. El mapa de calor ciudad-división para las divisiones con mayor error muestra que la mayor concentración del MAPE se ubica nuevamente en la división alojamiento, agua, electricidad, gas y otros combustibles, especialmente en varias ciudades de la Costa. En segundo plano aparecen alimentos y bebidas no alcohólicas, bebidas alcohólicas, tabaco y estupefacientes, recreación y cultura y transporte, aunque con intensidades claramente menores. Esta evidencia sugiere que la dificultad predictiva no se distribuye uniformemente dentro de la jerarquía del IPC, sino que responde a una combinación específica de componente y territorio.
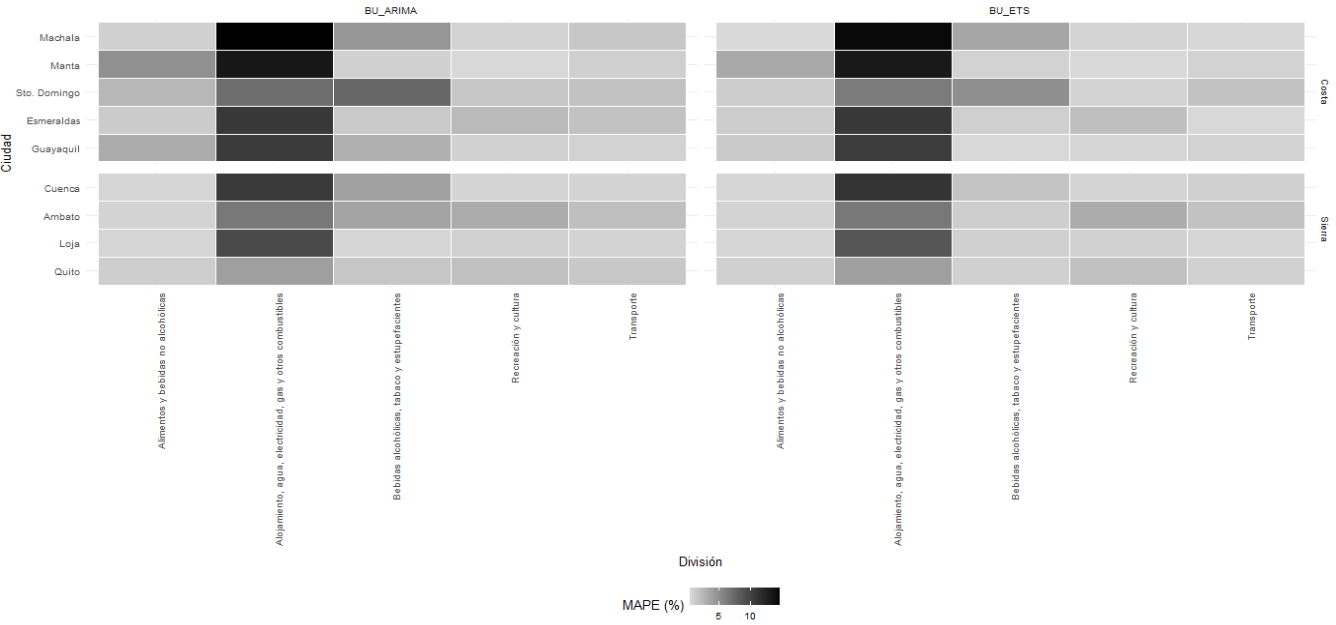
Fuente: INEC
Elaboración: autor
En conjunto, estos resultados permiten matizar la comparación agregada entre métodos. El menor MAPE del enfoque BU_ETS a nivel nacional no solo refleja una mejora en el índice total, sino también un desempeño más estable en la mayoría de ciudades y divisiones. En este sentido, la ventaja del enfoque propuesto no radica únicamente en reducir el error del agregado, sino en ofrecer una lectura más fina de dónde se originan las principales dificultades de pronóstico dentro de la estructura del IPC.
4.2 Sensibilidad mediante ventana rodante
Con el fin de evaluar la estabilidad de los hallazgos obtenidos en el ejercicio principal, se implementó un análisis de sensibilidad mediante ventana rodante (rolling window), manteniendo constante el tamaño de la muestra de entrenamiento y exigiendo, en cada iteración, un pronóstico a 12 meses. Este procedimiento permite examinar el desempeño relativo de los modelos cuando el horizonte de proyección es fijo y, al mismo tiempo, la cantidad de información histórica disponible para la estimación permanece constante entre ejecuciones.
Los resultados de este ejercicio se presentan en la tabla 2, donde se reportan, para cada método, el número de orígenes de evaluación y los valores promedio de MAE, MAPE y RMSE obtenidos sobre los bloques de 12 meses pronosticados. La evidencia vuelve a favorecer a los enfoques desagregados. En particular, bottom-up ETS (BU_ETS) registra el mejor desempeño global, con un MAE promedio de 0.91, un MAPE promedio de 0.80 % y un RMSE promedio de 1.11 %. En segundo lugar, se ubica bottom-up ARIMA (BU_ARIMA), con un MAE promedio de 0.96, un MAPE promedio de 0.85 % y un RMSE promedio de 1.130.
| Método | Ventanas | MAE promedio | MAPE promedio | RMSE promedio |
|---|---|---|---|---|
| BU_ETS | 6 | 0.91 | 0.80 % | 1.11 |
| BU_ARIMA | 6 | 0.96 | 0.85 % | 1.13 |
| DIR_ARIMA | 6 | 1.05 | 0.93 % | 1.18 |
| DIR_ETS | 6 | 1.33 | 1.18 % | 1.53 |
Fuente: INEC
Elaboración: autor
Nota: MAE y RMSE en unidades del índice; MAPE en porcentaje.
Los modelos directos sobre el IPC agregado muestran un deterioro claro en comparación con los enfoques bottom-up. El modelo ARIMA (DIR_ARIMA) alcanza un MAPE promedio de 0.93 %, mientras que ETS (DIR_ETS) presenta el peor resultado del conjunto, con un MAPE promedio de 1.18 %, además de los mayores valores de MAE y RMSE. En términos relativos, esto implica que el mejor método desagregado bottom-up ETS (BU_ETS) reduce el error porcentual promedio en aproximadamente 31.9 % frente a DIR_ETS, lo que refuerza la idea de que la estructura ciudad-división contiene información útil que no es plenamente capturada por el modelado directo del índice total.
Este resultado es relevante por dos razones. En primer lugar, confirma que la superioridad del enfoque bottom-up no aditivo no depende exclusivamente del esquema de validación desde un único punto de origen, sino que también se mantiene cuando el ejercicio se replantea bajo una lógica de ventana rodante. En segundo lugar, muestra que, dentro del conjunto de métodos considerados, el modelo ETS desagregado exhibe la mejor combinación de precisión y estabilidad cuando se exige al sistema producir trayectorias de 12 meses con una cantidad constante de información histórica.
En síntesis, la evidencia reportada en la tabla 2 sugiere que el enfoque bottom-up no aditivo es robusto a cambios en la estrategia de validación y que su ventaja frente a los modelos agregados directos persiste incluso bajo un criterio de evaluación más exigente. Esta consistencia fortalece la validez empírica de la propuesta y respalda su utilidad como alternativa para el pronóstico del IPC ecuatoriano.
4.3 Proyecciones individuales
Una ventaja adicional del enfoque propuesto es que no se limita a generar un pronóstico para el IPC nacional agregado, sino que permite obtener trayectorias proyectadas para niveles inferiores de la jerarquía. A partir del modelo final (bottom‑up con ETS), se construyen pronósticos por región y división de gasto, así como por ciudad. Los pronósticos puntuales (medias) se obtienen agregando linealmente las predicciones desagregadas mediante los ponderadores oficiales del INEC, lo que garantiza que sean coherentes con la estructura del índice: la agregación ponderada de los pronósticos de ciudad‑división reproduce exactamente el pronóstico puntual del IPC nacional.
Sin embargo, es importante señalar que esta coherencia se limita exclusivamente a los pronósticos puntuales. Las bandas de incertidumbre que se presentan a continuación se construyen agregando linealmente los límites inferiores y superiores de los intervalos de confianza (95 %) obtenidos de los modelos ETS individuales para cada serie ciudad‑división. Dicha agregación lineal no asegura que los intervalos resultantes sean probabilísticamente coherentes con la jerarquía (por ejemplo, que un intervalo de una división sea consistente con el intervalo de la ciudad o del total nacional). En rigor, la obtención de intervalos o distribuciones jerárquicamente reconciliadas requiere métodos avanzados (bootstrapping jerárquico, reconciliación de cuantiles o enfoques bayesianos) que quedan fuera del alcance de este trabajo. Por lo tanto, las bandas mostradas deben interpretarse como una referencia ilustrativa de la incertidumbre propia de cada nivel desagregado, no como intervalos formalmente reconciliados.
Dicha aclaración permite interpretar correctamente las figuras que siguen: las trayectorias puntuales son coherentes entre niveles, mientras que las bandas reflejan la agregación lineal de los intervalos individuales sin garantía de coherencia jerárquica.
En términos generales, se observa que las trayectorias puntuales no son homogéneas entre componentes. Algunas divisiones exhiben niveles más elevados y bandas de incertidumbre más amplias, mientras que otras muestran una evolución más estable y predecible. En ambos dominios regionales, la división alojamiento, agua, electricidad, gas y otros combustibles destaca por presentar la mayor amplitud en los intervalos agregados, lo que sugiere una mayor sensibilidad de este componente a cambios discretos y episodios de volatilidad. En contraste, divisiones como salud, transporte, comunicaciones o prendas de vestir y calzado muestran trayectorias puntuales más suaves y abanicos de predicción relativamente más contenidos.
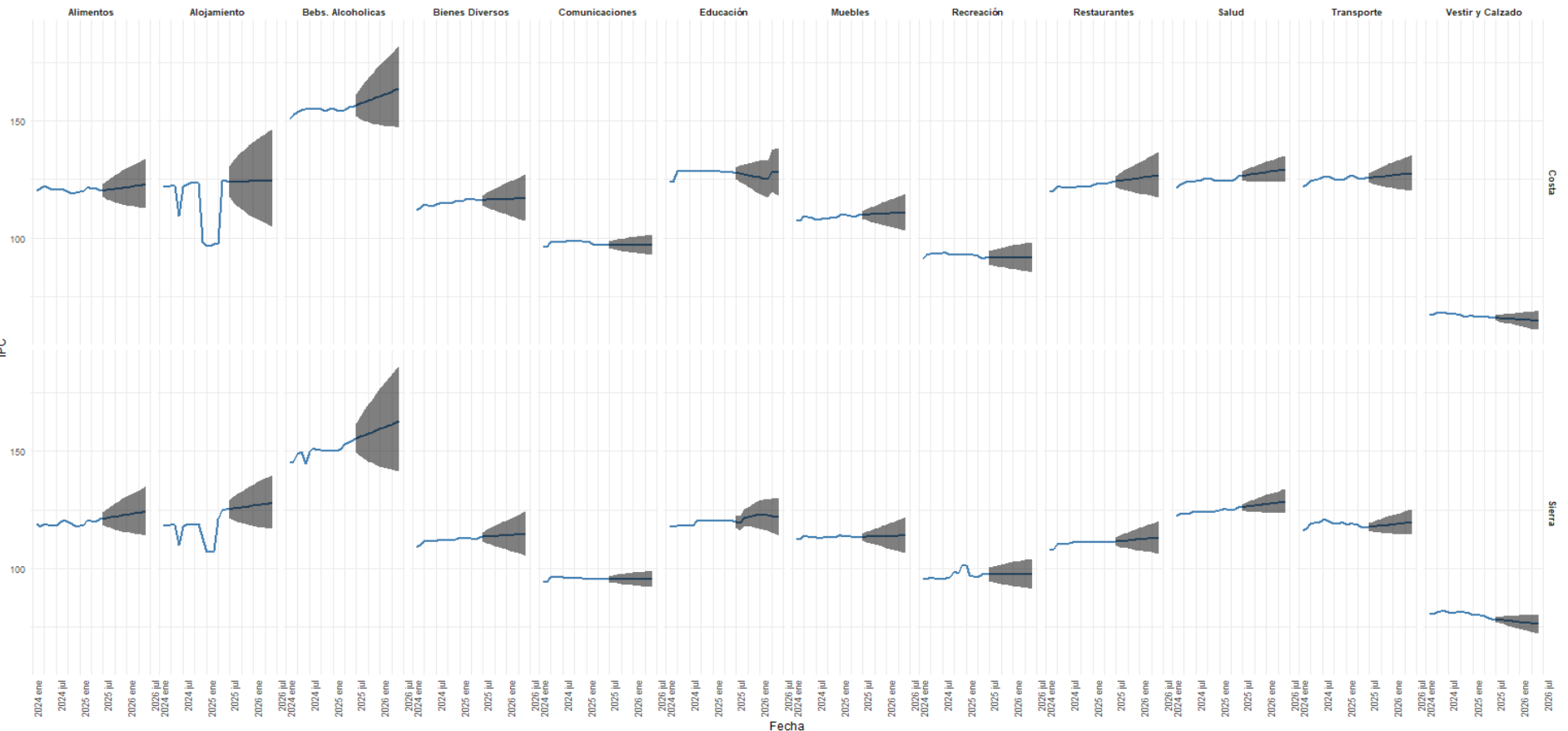
Fuente: INEC
Elaboración: Autor
Las proyecciones puntuales también sugieren diferencias entre Costa y Sierra. Si bien en ambas regiones predomina una trayectoria moderadamente ascendente en varios componentes, la intensidad del cambio no es idéntica. En algunos casos, la Costa presenta mayores niveles proyectados, mientras que en la Sierra ciertas divisiones mantienen una trayectoria más estable. Esta heterogeneidad confirma que la inflación no evoluciona de manera uniforme en el territorio ni entre categorías de gasto, y que un enfoque puramente agregado tiende a ocultar estas diferencias.
A nivel de ciudad, las nueve ciudades consideradas presentan una evolución puntual relativamente contenida, con una inclinación moderadamente positiva hacia el horizonte de pronóstico. No obstante, también aquí se observan diferencias en niveles y en amplitud de los intervalos agregados. Ciudades como Cuenca, Esmeraldas y Machala muestran niveles proyectados comparativamente más altos dentro del conjunto, mientras que Quito, Loja y Ambato exhiben trayectorias algo más moderadas. En todos los casos, las bandas de predicción se amplían conforme aumenta el horizonte, como es esperable en cualquier ejercicio de pronósticos, aunque sin perder una forma general ordenada y consistente con la dinámica reciente de cada serie.
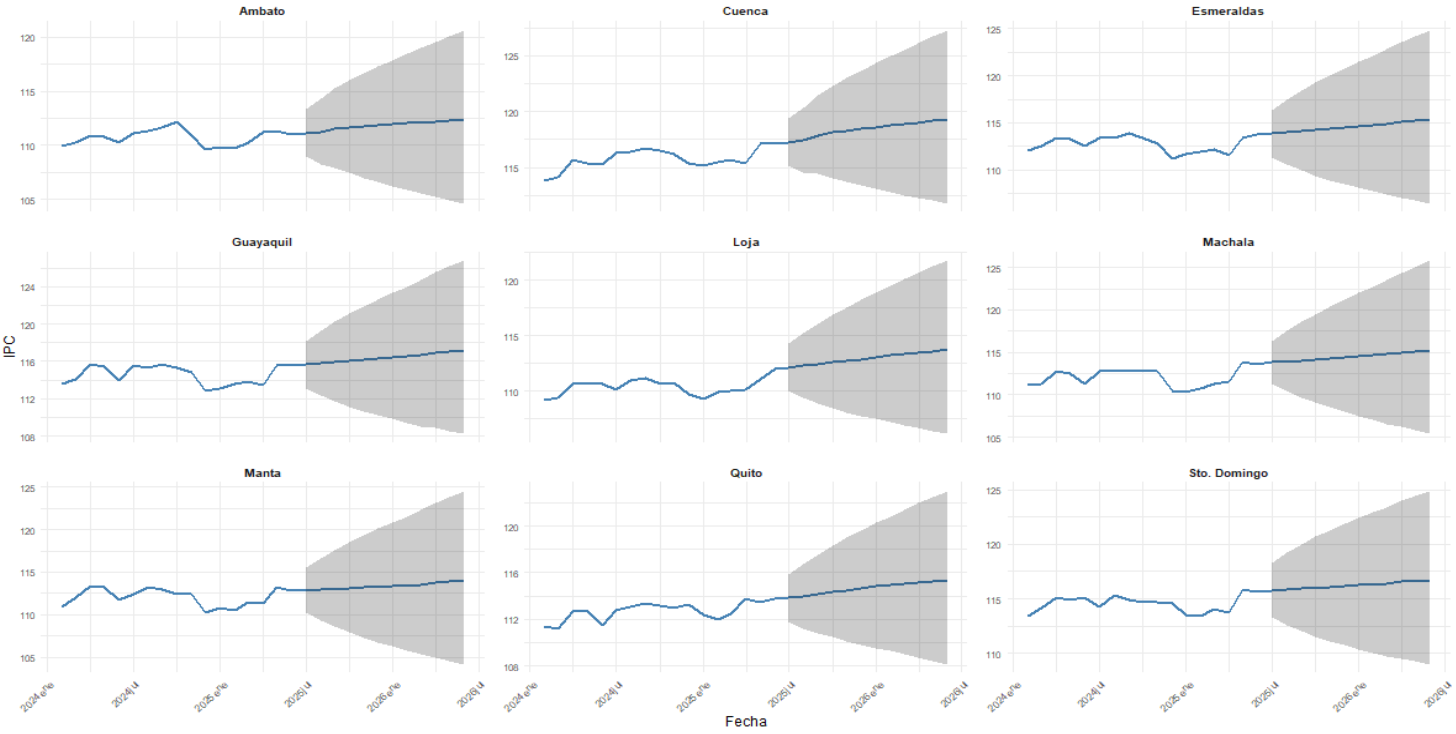
Fuente: INEC
Elaboración: Autor
En conjunto, estas proyecciones desagregadas muestran que el enfoque bottom‑up no aditivo aporta algo más que una mejora en la precisión del pronóstico puntual del IPC nacional. Su principal valor adicional radica en que permite producir pronósticos puntuales coherentes para niveles inferiores de la jerarquía, lo que facilita una lectura más rica de la inflación esperada. En lugar de disponer únicamente de una proyección agregada, el analista puede identificar qué regiones, ciudades o divisiones concentran mayores niveles proyectados, generando insumos útiles para el seguimiento económico y la interpretación sectorial de la trayectoria futura de los precios.
El análisis por divisiones de gasto revela que los componentes más volátiles, como alojamiento y bebidas alcohólicas, presentan los mayores desafíos predictivos a corto plazo, con intervalos individuales agregados más amplios. En contraste, divisiones con precios más administrados o regulados, como alimentos, transporte y salud, muestran trayectorias puntuales más suaves y pronósticos más precisos (intervalos agregados más estrechos).
En la misma línea, la desagregación a nivel de ciudad permite identificar patrones que pueden quedar enmascarados si solo se proyecta el IPC agregado. Ciudades como Cuenca, Loja y Esmeraldas presentan una tendencia puntual superior a las demás ciudades consideradas por el INEC, donde la trayectoria es más moderada.
4.4 Limitaciones
A pesar de los resultados razonables obtenidos, el estudio presenta algunas limitaciones que deben considerarse al interpretar los hallazgos. En primer lugar, el análisis se restringe a una familia relativamente acotada de modelos univariantes, concretamente ETS y ARIMA, por lo que no incorpora otras alternativas potencialmente relevantes, como modelos con variables exógenas, enfoques bayesianos o métodos de aprendizaje automático. En segundo lugar, la evaluación se concentra en la experiencia ecuatoriana y en la estructura específica del IPC base 2014, de modo que la generalización de los resultados a otros contextos o cambios metodológicos del índice debe hacerse con cautela.
En tercer lugar, aunque la estrategia rolling window aporta una prueba de sensibilidad útil, el número de ejecuciones posibles sigue siendo reducido, dado que la combinación entre tamaño de ventana y horizonte de 12 meses limita la cantidad de bloques evaluables. Por ello, los resultados de esta sensibilización deben interpretarse como evidencia complementaria y no como una prueba definitiva en sí misma. Finalmente, al trabajar con ponderadores fijos, el ejercicio asume estabilidad en la estructura de gasto utilizada para la agregación, lo que simplifica el análisis, pero deja fuera posibles cambios en los patrones de consumo a lo largo del tiempo.
Aun con estas limitaciones, la evidencia obtenida sugiere que, dentro del conjunto de métodos considerados, los enfoques bottom-up no aditivos constituyen una alternativa empíricamente favorable frente al modelado directo del IPC agregado.
5 Conclusiones y discusión
Este estudio evaluó la capacidad predictiva de un enfoque jerárquico no aditivo para el pronóstico del índice de precios al consumidor del Ecuador, comparándolo con modelos directos estimados sobre el IPC nacional agregado. La evidencia empírica favorece de manera consistente a los enfoques bottom-up, tanto en el ejercicio principal de pronóstico desde un único punto de origen como en la sensibilidad realizada mediante ventana rodante.
En el esquema principal, el mejor desempeño correspondió a BU_ETS, que registró los menores valores de MAE, MAPE y RMSE frente a los modelos directos y frente a la alternativa bottom-up con ARIMA. Este resultado sugiere que el aprovechamiento de la información desagregada por ciudad y división de gasto mejora la precisión del pronóstico del índice agregado, en comparación con el modelado univariante directo del IPC nacional.
Los resultados de la estrategia rolling window refuerzan esta conclusión. Bajo un esquema más exigente, con ventana fija y horizonte de 12 meses, los modelos bottom-up continuaron mostrando menor error promedio que los modelos directos. En particular, BU_ETS volvió a ubicarse como la especificación con mejor desempeño global, lo que aporta evidencia adicional sobre la estabilidad del enfoque propuesto.
En términos metodológicos, el trabajo muestra que la combinación de modelamiento individual de series desagregadas y agregación mediante ponderadores oficiales constituye una alternativa empíricamente sólida para el pronóstico del IPC ecuatoriano. La ventaja del enfoque no radica únicamente en la mejora del índice agregado, sino también en su capacidad para conservar el detalle de los componentes subyacentes del sistema de precios.
Finalmente, el enfoque propuesto ofrece un valor adicional al permitir generar pronósticos desagregados por ciudad y división, lo que amplía su utilidad para el análisis económico. Esta característica permite complementar el pronóstico del índice nacional con información más específica sobre la dinámica inflacionaria de sus componentes, abriendo espacio para futuras extensiones metodológicas y aplicaciones de política más focalizadas.
En síntesis, los hallazgos de esta investigación sugieren que, para el caso analizado, el enfoque bottom-up constituye una alternativa empíricamente competitiva para mejorar la precisión de los pronósticos del IPC frente a los modelos directos considerados. Además, permite generar proyecciones desagregadas coherentes a nivel de ciudad y división, lo que amplía su utilidad para el análisis económico. No obstante, la evidencia reportada debe interpretarse a la luz del conjunto de modelos evaluados y de las limitaciones propias del ejercicio de validación.
Anexos
Anexo 1. Top de series originales y sus correcciones por valores atípicos
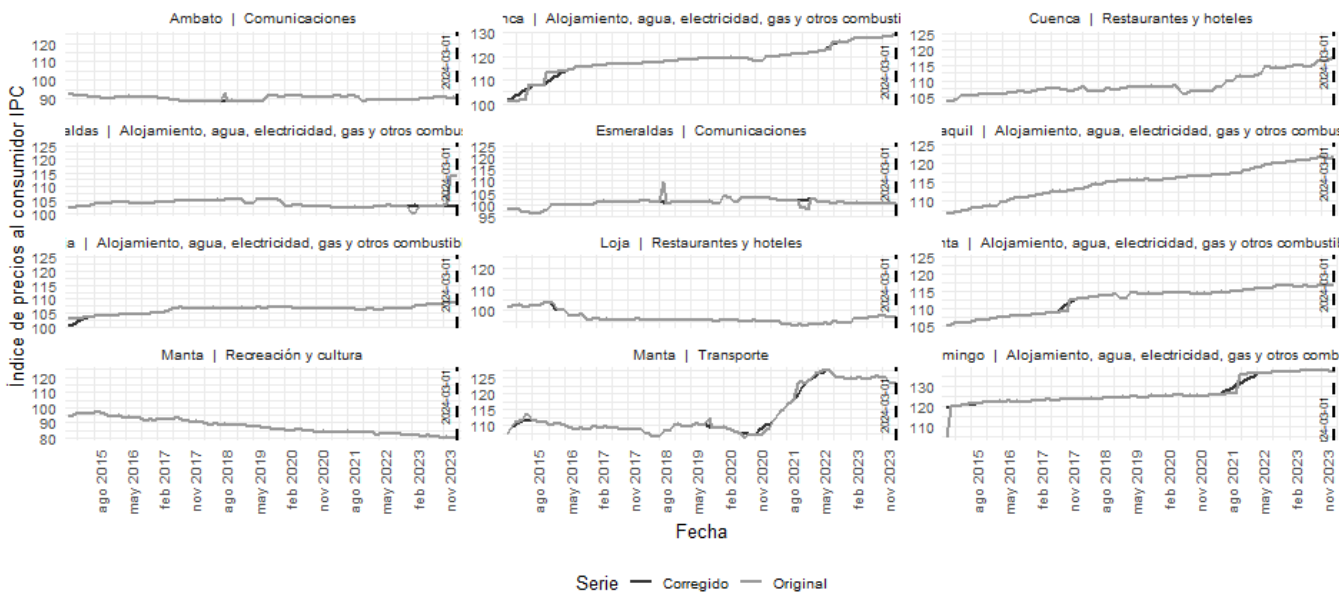
Fuente: INEC
Elaboración: Autor
Anexo 2. Distribución de familias y componentes de los modelos seleccionados
| Familia | Componentes clave | Frecuencia | Porcentaje |
|---|---|---|---|
| ARIMA | Sin estacionalidad, con drift | 39 | 36.11 % |
| ARIMA | Sin estacionalidad, sin drift | 18 | 16.67 % |
| ARIMA | Con estacionalidad | 27 | 25.00 % |
| ARIMA | Otros (no estacionales, órdenes altos) | 24 | 22.22 % |
| Total | 108 | 100 % | |
| ETS | Aditivo (A,A,N; A,Ad,N; A,N,N) | 54 | 50.00 % |
| ETS | Multiplicativo (M,N,N; M,A,N; M,Ad,N) | 43 | 39.81 % |
| ETS | Con estacionalidad aditiva o multiplicativa | 11 | 10.19 % |
| Total | 108 | 100 % |
Elaboración: autor
Anexo 3. Resultados del ejercicio de pronósticos estáticos
| Método | MAE | MAPE | RMSE |
|---|---|---|---|
| BU_ETS | 0.78 | 0.70 % | 1.06 |
| BU_ARIMA | 1.34 | 1.19 % | 1.57 |
| DIR_ETS | 1.89 | 1.67 % | 2.12 |
| DIR_ARIMA | 2.04 | 1.81 % | 2.22 |
Elaboración: autor
Nota: MAE y RMSE en unidades del índice; MAPE en porcentaje.